VS2005以降に追加されたキーワード__restrictを試す
本家で記載されている通り:最適化の推奨事項ポインタ操作に対して新しく__restrictキーワードが追加されました。
これは何?という方に簡単に説明すると、あるポインタAとあるポインタBがあった時に
コンパイラ側に対して、ポインタBは、ポインタAとは全く別に切り離された領域にある位置を
指すポインタですよ!!と教えることができるキーワードになります。
これがなぜ便利かというと、以下のようなコードがあった時に、ArraySumupに渡す引数がもし、
異なるポインタ同士であるということがコンパイラ側に伝われば、より最適なコードが吐かれることを期待できます。
具体的には、こんな感じ
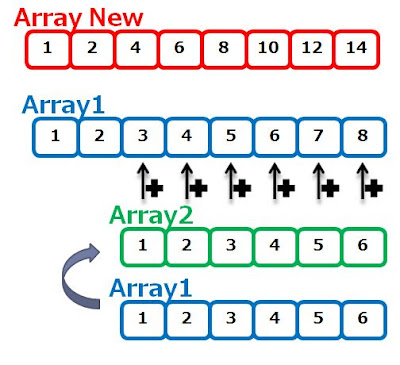
つまり同じ配列を渡したとしても、異なる配列として認識してくれて、且つ
CPUの命令セットによって、複数同時演算が可能であれば、上記のように
出力されてもらえると効率よく処理できるわけです。
アセンブリ疑似コード
R1 = array1[0]:array1[1]:array1[2]:array1[3] R2 = array2[0]:array2[1]:array2[2]:array2[3] R1 += R2 ; CPUの命令セットSIMD,MMX等により同時に演算してしまう。 array1 <- R1
#include "stdafx.h" #include <assert.h> #include <iostream> using namespace std; void ArraySumup( int n , int* __restrict dstArray , int* __restrict srcArray ); //void ArraySumup( int n , int* dstArray , int* srcArray ); void ArraySumup( int n , int* __restrict dstArray , int* __restrict srcArray ) //void ArraySumup( int n , int* dstArray , int* srcArray ) { assert( (n % 4)==0 ); for( int i = 0;i < n;i+=4 ) { dstArray[i] += srcArray[i]; dstArray[i+1] += srcArray[i+1]; dstArray[i+2] += srcArray[i+2]; dstArray[i+3] += srcArray[i+3]; } } int _tmain(int argc, _TCHAR* argv[]) { //int src[] = { 1,2,3,4,5,6,7,8,9,10 }; int dst[] = { 1,2,3,4,5,6,7,8,9,10 }; ArraySumup( 12 , dst+2 , dst ); for( int i = 0;i < sizeof(dst)/sizeof(int);i++ ) { cout << "DST["<<i<<"] = " << dst[i]<< endl; } return 0; }
ですが、実際に手元のVS2005 + x86 CPUを使ってコンパイルした結果は、
最適化あり:/Ox
; 15 : {
00000 56 push esi
00001 8b f0 mov esi, eax
; 16 : assert( (n % 4)==0 );
; 17 :
; 18 : for( int i = 0;i < n;i+=4 )
00003 8d 4a 0c lea ecx, DWORD PTR [edx+12]
00006 8d 46 04 lea eax, DWORD PTR [esi+4]
00009 2b d6 sub edx, esi
0000b 57 push edi
0000c be 03 00 00 00 mov esi, 3
$LL3@ArraySumup:
; 19 : {
; 20 : dstArray[i] += srcArray[i];
00011 8b 79 f4 mov edi, DWORD PTR [ecx-12]
00014 01 78 fc add DWORD PTR [eax-4], edi
; 21 : dstArray[i+1] += srcArray[i+1];
00017 8b 3c 02 mov edi, DWORD PTR [edx+eax]
0001a 01 38 add DWORD PTR [eax], edi
; 22 : dstArray[i+2] += srcArray[i+2];
0001c 8b 79 fc mov edi, DWORD PTR [ecx-4]
0001f 01 78 04 add DWORD PTR [eax+4], edi
; 23 : dstArray[i+3] += srcArray[i+3];
00022 8b 39 mov edi, DWORD PTR [ecx]
00024 01 78 08 add DWORD PTR [eax+8], edi
00027 83 c0 10 add eax, 16 ; 00000010H
0002a 83 c1 10 add ecx, 16 ; 00000010H
0002d 83 ee 01 sub esi, 1
00030 75 df jne SHORT $LL3@ArraySumup
00032 5f pop edi
00033 5e pop esi
; 24 : }
; 25 : }
結局は、同時に演算しないので、以下のように
1,2,4,6,9,12....となってしますのでご注意を。